18. April 2026 (Zuletzt aktualisiert: 3. Juni 2026)
AI Crawler, Markdown & Cloudflare: Bot-Optimierung

Wichtigste Erkenntnisse
- AI-Crawler scheitern oft an JavaScript und verschachteltem HTML (Rendering-Hölle) – sie brauchen strukturierte Daten.
- Markdown spart bis zu 80% Token, was die Verarbeitung für LLMs schneller, günstiger und präziser macht.
- Cloudflares 'Markdown for Agents' ist ein Gamechanger, um Bestandseiten ohne Relaunch KI-ready zu machen.
- Experten-Warnung: Hanns Kronenberg warnt vor 'zwei Wahrheiten' (Cloaking-Risiko für die KI).
Moin! 🌻
Machen wir uns nichts vor: Die meisten AI-Crawler sind aktuell noch ziemlich dumm.
Sie scheitern an komplexem JavaScript, verheddern sich in verschachteltem HTML-Code und verlieren die Orientierung in Navigations-Labyrinthen. Warum? Weil unser Web für Menschen gebaut wurde, nicht für Maschinen. Wir haben zwei Jahrzehnte damit verbracht, Webseiten für das menschliche Auge, für Retina-Displays und für blitzschnelle Interaktionen zu optimieren. Das Ergebnis? Ein gigantischer Berg an Code-Ballast, der für eine Künstliche Intelligenz (KI) oft nur eins ist: Lärm.
Bots brauchen keine CSS-Animationen oder bunte Header-Grafiken. Sie brauchen Daten. Pure, unverfälschte Information. Und hier liegt die Krux: Wer seine wertvollen Inhalte hinter technischem Pfusch versteckt, wird in der Welt der Large Language Models (LLMs) schlichtweg nicht stattfinden.
AI Crawler & Cloudflare: Warum Markdown die Lösung ist
Wenn ein LLM wie ChatGPT oder Claude eine klassische Website crawlt, muss es sich durch hunderte Zeilen HTML-Ballast wühlen, um den eigentlichen Kerninhalt zu finden. Stell dir vor, du müsstest ein Buch lesen, bei dem auf jeder Seite zwischen den Sätzen die Konstruktionspläne des Druckers stehen. Das ist das “Erlebnis”, das wir Bots aktuell bieten.
Das Problem ist dreifaltig:
- Rechenpower: Das Token-Limit (die “Gedächtnisspanne” der KI) wird unnötig belastet. Jedes
<div>, jedes<span>und jede CSS-Klasse frisst Token, die eigentlich für die Antwort übrig sein sollten. - Genauigkeit: Informationen werden falsch kontextualisiert. Wenn der Bot den Footer-Text als Teil des Hauptartikels liest, entstehen Halluzinationen.
- Geld: Mehr Token bedeuten höhere Kosten für die Bot-Betreiber. Und rate mal, welche Seiten ein Bot bevorzugt crawlt, wenn er die Wahl hat? Genau: Die effizienten.
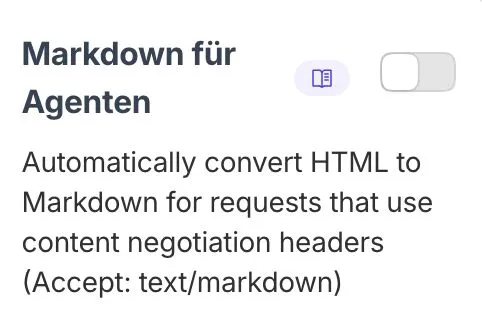
Cloudflare hat das erkannt und mit “Markdown for Agents” einen echten Hebel angesetzt. Die Idee: Eine Website liefert dem menschlichen Besucher das volle Design-Erlebnis, dem AI-Bot aber eine schlanke, präzise Markdown-Version.
Das Ergebnis: 80% Token-Ersparnis
Die Zahlen aus der Praxis sind beeindruckend. Durch die Konvertierung in Markdown lässt sich der Token-Verbrauch um bis zu 80% reduzieren. Das ist kein kleiner “Speed-Boost”, das ist eine Revolution in der Art und Weise, wie wir Maschinen mit Wissen füttern.
Was heißt das für dein Business?
- Deine Inhalte werden von der KI schneller erfasst.
- Die Antworten der KI über dein Unternehmen werden präziser, weil der Kontext klarer ist.
- Du sinkst in der “Wahrnehmungshürde” der Bots, weil du ihnen die Arbeit abnimmst.
💬 Jörgs SEO-Klartext (LinkedIn Insights)
"KI-Strategie ist Chefsache, keine Aufgabe für den Praktikanten. Wer seine Seite nicht maschinenlesbar macht, existiert in der Welt von morgen schlichtweg nicht mehr. Cloudflare macht hier vor, wie man den Pfusch am Bau der 2020er Jahre aufräumt. Wir müssen anfangen, in 'Agent Readiness' zu denken."
Stimmen aus der Community: Die Experten-Dilemmas
Ich habe dieses Thema neulich auf LinkedIn diskutiert und dabei sind drei kritische Punkte aufgetaucht, die man nicht ignorieren darf, wenn man AI-SEO ernst meint.
1. Hanns Kronenberg: Die Gefahr der “zwei Wahrheiten”
Hanns Kronenberg, einer der profundesten Köpfe der deutschen SEO-Szene, hat den Finger in die Wunde gelegt. Das Problem: Wenn wir dem Menschen HTML und der Maschine Markdown liefern, erschaffen wir zwei unterschiedliche Wahrheiten für ein und dieselbe URL.
Was passiert, wenn der Markdown-Inhalt vom HTML-Inhalt abweicht? Für Suchmaschinen wie Google riecht das nach “Cloaking” – einer uralten Black-Hat-Technik. Hanns warnt davor, dass der Aufwand für die Suchsysteme steigt, wenn sie Markdown-Versionen gegen HTML-Versionen validieren müssen, um Spam auszuschließen. Es ist eine technologische Herausforderung, die wir erst noch meistern müssen.
2. Alexander Außermayr: Das Cloudflare-Monopol
Alexander Außermayr hat einen sehr berechtigten infrastrukturellen Einwand gebracht. Wir verlassen uns immer mehr auf Cloudflare. Wenn dieser Dienstleister das “Markdown-Tor” zur Welt kontrolliert, entsteht eine gefährliche Abhängigkeit. Alexander erinnerte an die großen Cloudflare-Ausfälle von 2025: “Da ging für mehrere Stunden einfach NIX mehr.”
Ein Internet, das nur noch durch den Cloudflare-Filter für KIs lesbar ist, ist ein fragiles Internet. Wir müssen uns fragen: Wollen wir die Kontrolle über unsere Sichtbarkeit wirklich komplett an einen Intermediär abgeben oder sollten wir unsere Seiten nativ so bauen, dass sie für Agenten lesbar sind?
3. Markus Amalaraj: Das JavaScript-Schlamassel
Markus kam mit dem “Realitäts-Check” für Frontend-Entwickler um die Ecke. Cloudflares Lösung funktioniert (aktuell) vor allem für serverseitig gerenderte (SSR) Inhalte. Wer seine Seite jedoch als reiner Client-Side-Rendering (CSR) Pfusch (SPA, AJAX-Hölle) betreibt, schaut in die Röhre.
Wenn der Inhalt erst im Browser des Nutzers zusammengebaut wird, sieht der Cloudflare-Wandler oft nur eine leere Hülle. Das bedeutet: Wer auf Frameworks wie React oder Vue setzt, ohne korrektes SSR-Setup, bleibt auch mit Markdown-Filtern für die KI “dumm”.
Content Negotiation: So funktioniert es technisch sauber
Ein wichtiger Punkt, den ich in der Diskussion klären konnte: Wie erkennt Cloudflare eigentlich, dass ein Agent (Bot) anklopft?
Früher hat man das über “User-Agent-Sniffing” gelöst – also dem Bot anhand seines Namens (z.B. GPTBot) eine andere Seite gezeigt. Das ist fehleranfällig und unsauber. Der moderne Weg, den auch Cloudflare nutzt, ist Content Negotiation über den Accept-Header.
Fragt ein Browser an, schickt er Accept: text/html. Fragt ein moderner AI-Agent an, kann er sagen: Accept: text/markdown. Der Server versteht das und liefert das gewünschte Format. Das ist kein Cloaking, sondern eine saubere technische Aushandlung zwischen zwei Kommunikationspartnern. Es ist die Zukunft des Agent-SEO.
Jenseits der KI: Markdown für die Barrierefreiheit?
Ein überraschender und inspirierender Einwurf kam von Andre Herzog. Er fragte, ob wir diese sauberen Markdown-Versionen nicht auch für Menschen mit Einschränkungen nutzen könnten.
Stell dir vor, Screenreader müssten sich nicht mehr durch tonnenweise “Div-Suppe” wühlen, sondern könnten direkt auf das Markdown zugreifen. Eine textbasierte, barrierefreie Version des Internets, die durch die KI-Revolution quasi als Abfallprodukt abfällt. Das wäre ein echter Gewinn für die digitale Inklusion.
Bonus: Das “Agent Experience” (AX) Zeitalter
Wir haben uns jahrelang über UX (User Experience) den Kopf zerbrochen. Jetzt kommt AX (Agent Experience).
Was bedeutet das? AX bedeutet, dass wir anfangen müssen, unsere Inhalte so zu strukturieren, dass ein Agent (sei es Siri, Alexa, ChatGPT oder ein spezialisierter AI-Researcher) die Information in Millisekunden extrahieren kann, ohne rendern zu müssen.
Drei goldene Regeln für gutes AX:
- Semantische Präzision: Benutze keine schwammigen Begriffe. Wenn du “SEO für Zahnärzte” verkaufst, schreib nicht “Digitale Sichtbarkeit für Heilberufe”. Die KI ist wörtlich – hilf ihr dabei.
- Hierarchische Klarheit: Nutze H1 bis H3 Tags streng logisch. Markdown basiert auf Struktur. Wenn deine Struktur im HTML Pfusch ist, wird das Markdown-Extrakt auch Pfusch.
- Daten-Vollständigkeit: Verstecke keine harten Fakten (Preise, Öffnungszeiten, Inhaltsstoffe) hinter Interaktionen oder Buttons. Ein Agent klickt nicht “Mehr laden”. Er liest, was da ist.
Fazit: Pfusch am Bau korrigieren
Egal ob man Cloudflare nutzt, das französische Lightpanda (eine effiziente Alternative) oder seine Seite direkt nativ im Markdown-Format (über Header-Aushandlung) bereitstellt: Der Trend ist unumkehrbar. Der “Markdown-Standard” wird zum Fundament der neuen Suche.
Das Web der Zukunft ist zweigeteilt:
- Die Design-Ebene für Emotionen, Markenbildung und den menschlichen Nutzer. Hier darf es bunt, laut und animiert sein.
- Die Daten-Ebene für Struktur, Logik und den AI-Agenten. Hier muss es trocken, präzise und effizient sein.
Wer glaubt, er könne das Thema “Agent Readiness” aussitzen, wird sich in zwei Jahren wundern, warum ChatGPT und Co. nur die Konkurrenz zitieren. Es geht nicht darum, schönauszusehen. Es geht darum, verstanden zu werden. Wer heute seine Hausaufgaben macht, sichert sich die Pole-Position für die Sichtbarkeit in einer Welt, in der maschinelle Empfehlungen den Ton angeben.
Wie siehst du das? Diskutiere mit mir und der Community direkt auf LinkedIn:
👉 Hier geht’s zur LinkedIn-Diskussion zum Thema AI-Crawler
Habe fertig.
ALOHA! 🌻✌️
Bist du bereit für das AI-Zeitalter?
In meiner SEO-Sprechstunde analysieren wir nicht nur deine Rankings bei Google, sondern auch deine Sichtbarkeit in KI-Systemen. Mit Rankscale machen wir den Check.
Jetzt Vision-Check anfragenWeiterführende Artikel & Quellen
- Lese-Tipp: GEO Action Plan: So wirst du in LLMs sichtbar
- Lese-Tipp: Grounding Page Generator: AI-SEO für Fortgeschrittene
- Lese-Tipp: Agent Readiness Glossar: Das 1x1 der Maschinenlesbarkeit
- Quelle: Cloudflare - Introducing Markdown for Agents
Warum brauchen AI-Crawler Markdown?
Was ist das Problem mit JavaScript?
Wie verbessert Cloudflare die Sichtbarkeit?
Lohnt sich der Aufwand für AI-SEO jetzt schon?
Diesen Beitrag teilen?
Vielleicht hilft er ja auch anderen in deinem Netzwerk.